That’s why Labelbox vs Scale AI is still the comparison I hear most in 2026. Both can handle serious volume. Both are built around human-in-the-loop workflows. Both have moved hard toward RLHF, evals, and multimodal data as LLM projects have grown up.
What’s different is the operating model: who runs the factory, how much you can tune it, and how predictable it feels once you’re labeling at scale.
What enterprise data labeling looks like in 2026 (and why it’s messier than it sounds)
In 2026, “labeling” often includes tasks that feel closer to product QA than classic annotation:
- Preference ranking and rubric scoring for LLM outputs (the stuff that powers RLHF and evaluation).
- Multimodal chat tasks, where a single item can include text, an image, and tool-use traces.
- Faster loops between training, error analysis, and re-labeling.
I’ve learned to treat labeling platforms like I treat deployment tooling: the UI matters, but the real question is whether the system holds up under pressure. Audit trails, review queues, and access control can matter as much as polygon tools.
For broader context on how these platforms sit in the market, I like cross-checking independent roundups such as Second Talent’s list of enterprise data annotation tools and comparisons like Alation’s breakdown of data labeling tools. They don’t replace hands-on testing, but they help me sanity-check my shortlist.
Labelbox in 2026: platform-first, with services when you want them
Labelbox’s center of gravity is the platform. When I evaluate it for an enterprise team, I think “do we want our own operators in the cockpit?” If yes, Labelbox tends to feel natural.
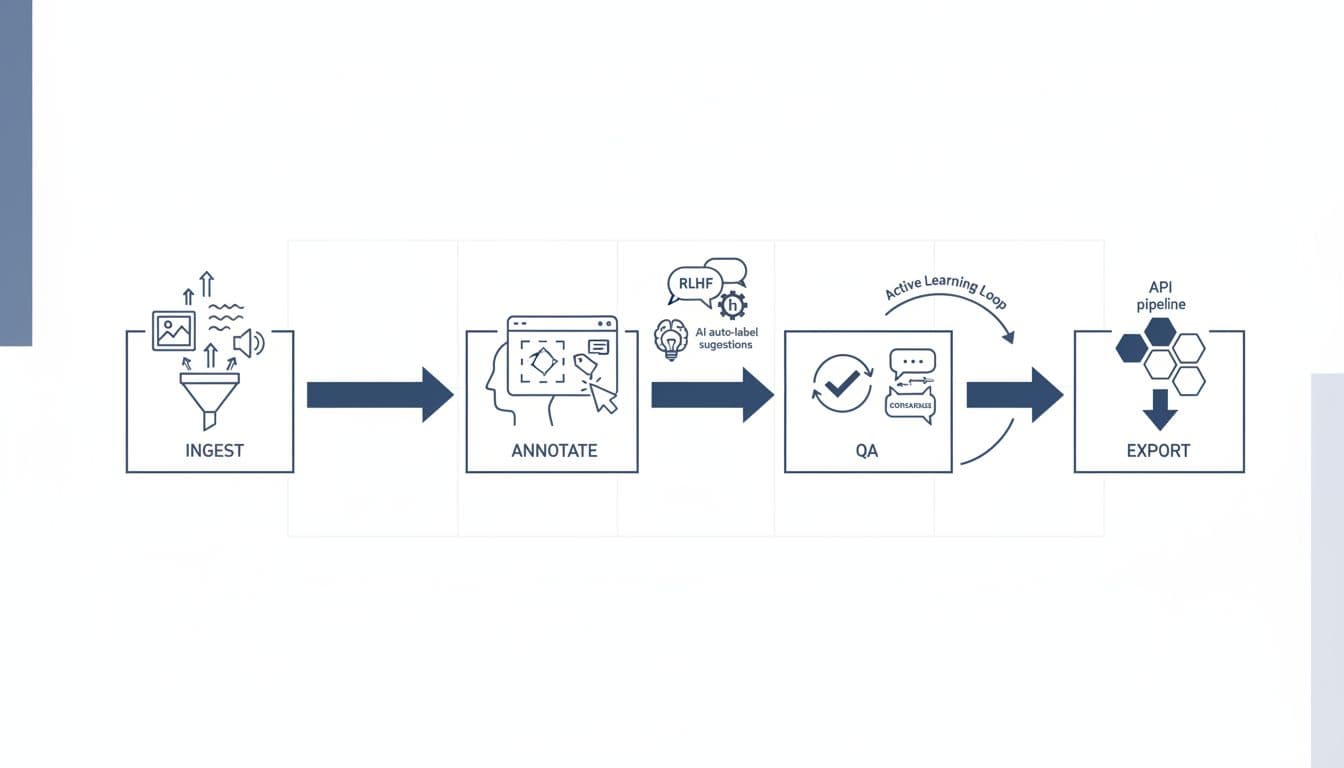
Here’s what stands out to me in 2026:
Strong coverage of modern data types. Labelbox supports images and video, plus text workflows and formats like PDFs, audio, geospatial, and multimodal chat style datasets. For teams building LLMs, that breadth reduces the number of side tools you end up duct-taping together.
Built-in RLHF and evaluation workflows. The platform has leaned into supervised fine-tuning datasets, preference labeling, and rubric-based evaluation flows. In practice, this means less time inventing your own “spreadsheet-as-an-eval-tool” process.
A clear story for AI-assisted labeling. Model-assisted labeling and automation can speed up throughput, but it can also hide mistakes. Labelbox’s approach is designed around using models to propose work, then routing to humans for review and correction.
Pricing that starts self-serve, then scales up. As of early 2026, Labelbox uses usage-based billing tied to Labelbox Units (LBUs), and it has a free tier for testing. For enterprise, you should still expect a contract, but I like that it’s easier to run a real pilot before the procurement machine kicks in.
If you want to see how Labelbox frames the head-to-head, their own page is here: Labelbox vs Scale AI. I read vendor comparisons like I read product marketing (useful, but biased), and I validate claims with a pilot.
One more thing: when I’m judging tooling, I stick to a consistent rubric so I don’t get swayed by glossy demos. My baseline is the same approach I use across the site, described in how we review AI tools at AI Flow Review.
Scale AI in 2026: managed execution at high volume
Scale AI, in my experience, is best understood as “we’ll run the operation.” Yes, there’s a platform. But the real product is the combination of tooling plus a large managed workforce and mature QA processes.
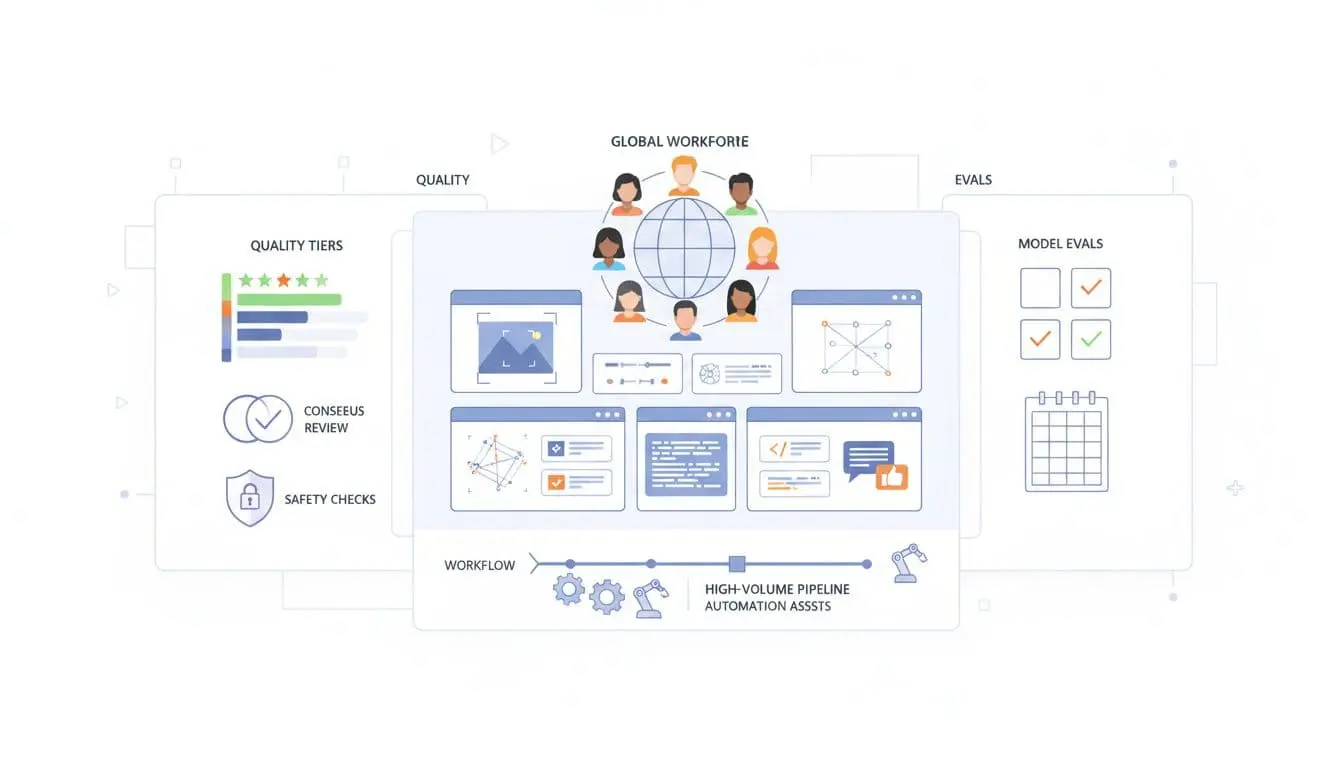
What I associate with Scale AI in 2026:
Depth for high-stakes modalities. Scale is well-known for autonomy style workloads (think 3D and LiDAR, sensor fusion, and complex perception tasks), along with text and conversational RLHF work. If your roadmap includes robotics, automotive, or other perception-heavy domains, this can matter.
A service model that reduces internal headcount. If you don’t want to staff a labeling operations team, Scale’s managed approach can be the difference between shipping and stalling. You trade some control for speed and execution.
Quality tiers and layered review. Scale’s reputation is built around repeatable QA, including gold sets, consensus methods, and review hierarchies. That structure often shows up in enterprise deals where failure costs real money.
Contract-based pricing. Scale doesn’t publish a simple price list. You should expect volume-based enterprise contracts. This can be fine, but it also means your pilot plan needs to be negotiated, not just clicked into existence.
For a neutral snapshot that includes other vendors too, I sometimes point teams to SourceForge’s comparison page for Labelbox, Scale, and Appen. I don’t treat it as gospel, but it’s a quick way to see what features buyers tend to compare.
Labelbox vs Scale AI: where the differences show up in real enterprise use
The simplest way I explain it is this: Labelbox feels like buying factory equipment and hiring some contractors, Scale AI feels like hiring a contract manufacturer that brings its own factory.
Here’s my practical side-by-side:
| Buying question | Labelbox (my read) | Scale AI (my read) |
|---|---|---|
| Who runs day-to-day ops? | Your team (with optional services) | Scale’s managed teams often run it |
| Best fit for | Teams that want control, iteration speed, and deep platform workflows | Teams that want outsourcing, high-volume delivery, and mature QA programs |
| RLHF and eval workflows | Strong focus, especially in-platform workflows | Strong focus, often as delivered service programs |
| Pricing feel | Usage-based (LBUs) with a lower-friction start | Enterprise contracts, pricing varies by scope and quality tier |
A few “gotchas” I watch for on both sides:
Throughput vs truth. Fast labeling is useless if it’s wrong. I ask how each vendor measures inter-annotator agreement, how they handle ambiguous guidelines, and how quickly they can adapt when the model team changes the rubric mid-sprint.
Workflow transparency. I want to see where items get stuck (ingest, annotate, QA, escalation), plus who touched what and when. When audits happen, hand-wavy answers don’t work.
Security and data handling. Every enterprise says they care about this, but the question is whether the vendor can meet your actual needs (SSO, access control, network isolation options, retention policies). I put these in writing during the pilot.
If you’re also building customer-facing AI, the labeling platform is only part of the stack. For example, I’ve had teams tie eval sets to bot behavior tests, which is why I keep a close eye on tooling like Botpress too (my notes are in this Botpress chatbot platform review 2025).
My RFP checklist for enterprise teams (quick, but serious)
When I’m helping a team choose, I ask for proof, not promises:
- A paid pilot with your messy edge cases, not curated samples.
- Clear definitions for “quality” (accuracy, agreement, rubric adherence) and how it’s reported weekly.
- A workflow map showing QA layers, escalation, and issue resolution.
- Export formats and APIs that fit your training and evaluation pipelines.
- A pricing model that won’t surprise you when volume spikes.
Where I land in 2026
If I want maximum control, fast iteration on RLHF and eval workflows, and a platform my team can operate directly, I lean Labelbox. If I want to outsource the labeling operation at large scale, with deep QA programs and less internal staffing, I lean Scale AI.
Either way, I don’t sign until I’ve run a real pilot with real pain points. In Labelbox vs Scale AI, the winner is usually the one that matches how you actually work, not how you wish your org worked.