
If you’re shipping an LLM app in 2026, prompt injection isn’t a “maybe” problem. It’s a daily reality, especially once your bot can browse, call tools, read files, or pull from a database. One weird message can act like a crowbar on your system prompt.
In this Lakera Guard review, I’m focusing on the stuff that actually matters when you’re building real products: how well it blocks prompt injection, what false positives feel like in production, and how long setup takes when you’re not doing a demo, you’re doing a release.
What Lakera Guard is (and why it’s showing up everywhere in 2026)
Lakera Guard is a runtime security layer for LLM apps. The simple idea is: before content hits your model (and before the model’s output goes back to a user or tool), Guard checks it for threats like prompt injection and related abuse patterns.
As of early 2026, Lakera is now part of Check Point, which signals where this category is going: security teams want LLM defense to look and feel like other security controls, not a bunch of custom regex and wishful thinking.
I also like that Lakera Guard is positioned as model-agnostic, meaning it can sit in front of many LLM stacks without forcing you into one vendor.
If you’re comparing broader options in this space, I keep a running shortlist in my own roundup of Top AI security tools for 2025, since most teams still buy platforms on annual cycles.
Prompt-injection blocking in real apps (direct, indirect, and agent flavored)
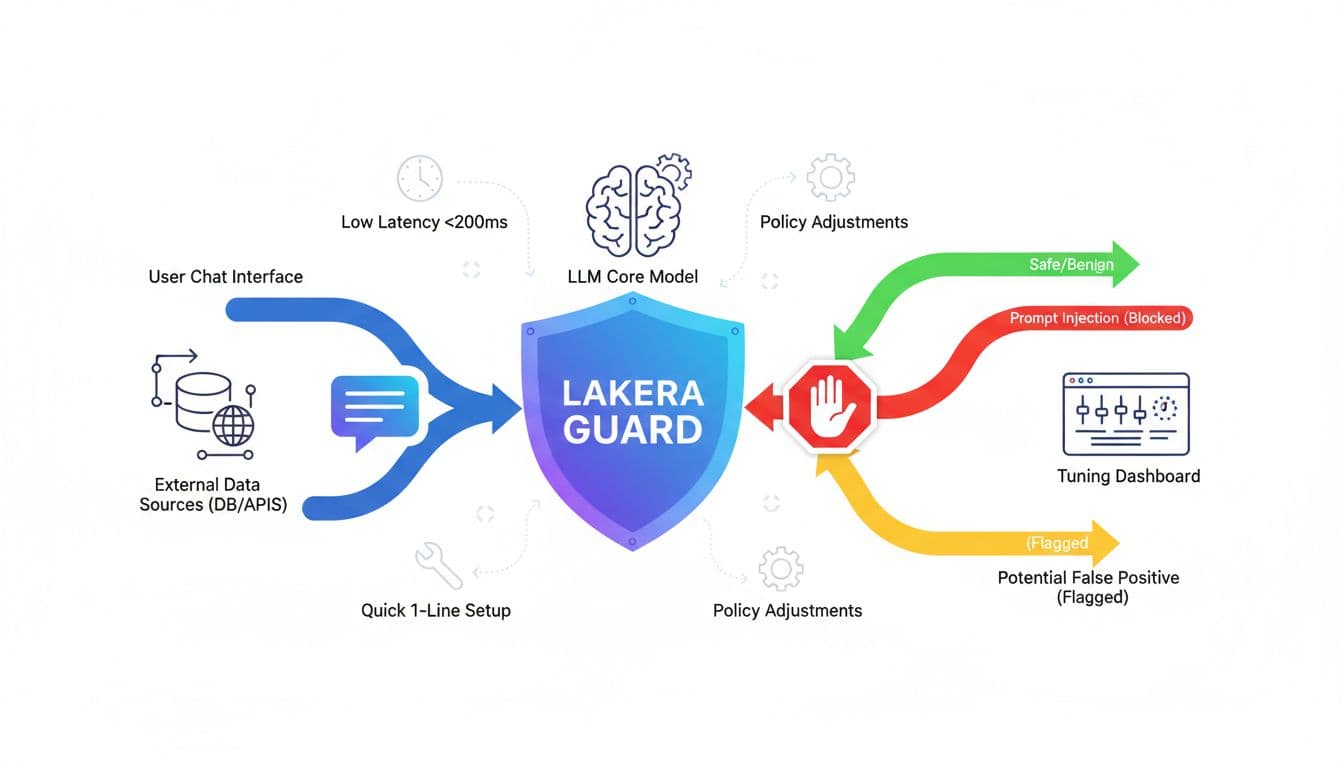
Prompt injection is basically instruction hijacking. The attacker tries to override your app’s rules by stuffing new rules into the user message or into content your app fetches. The “indirect” version is the scarier one, it hides in a web page, a document, or a tool response, and then your agent reads it and obeys it.
Lakera’s own primer on prompt injection attacks is worth scanning because it breaks down the mechanics in plain terms.
From current public updates, Lakera Guard is designed to catch:
- Direct prompt injections (classic “ignore your instructions” type content)
- Indirect prompt injections (poisoned web pages, retrieved docs, plugin output)
- Prompt extraction attempts (trying to pull out the system prompt)
- Jailbreak patterns, including obfuscated and role-play style bypass attempts
One detail that matches what I see in the field: attackers don’t stop at one tactic. Q4 2025 activity cited for Guard-protected apps included adapted agent attacks, including system prompt extraction and subtle bypasses that hide inside “safe sounding” scenarios. That’s exactly how real abuse looks, like a harmless story that quietly asks your agent to break rules.
If you want more context on why these runtime attacks keep growing, VentureBeat’s overview of runtime attacks breaking AI security captures the bigger pattern: the threat moves to where inference happens, not where the model was trained.
False positives: what they look like, why they happen, and how I’d manage them
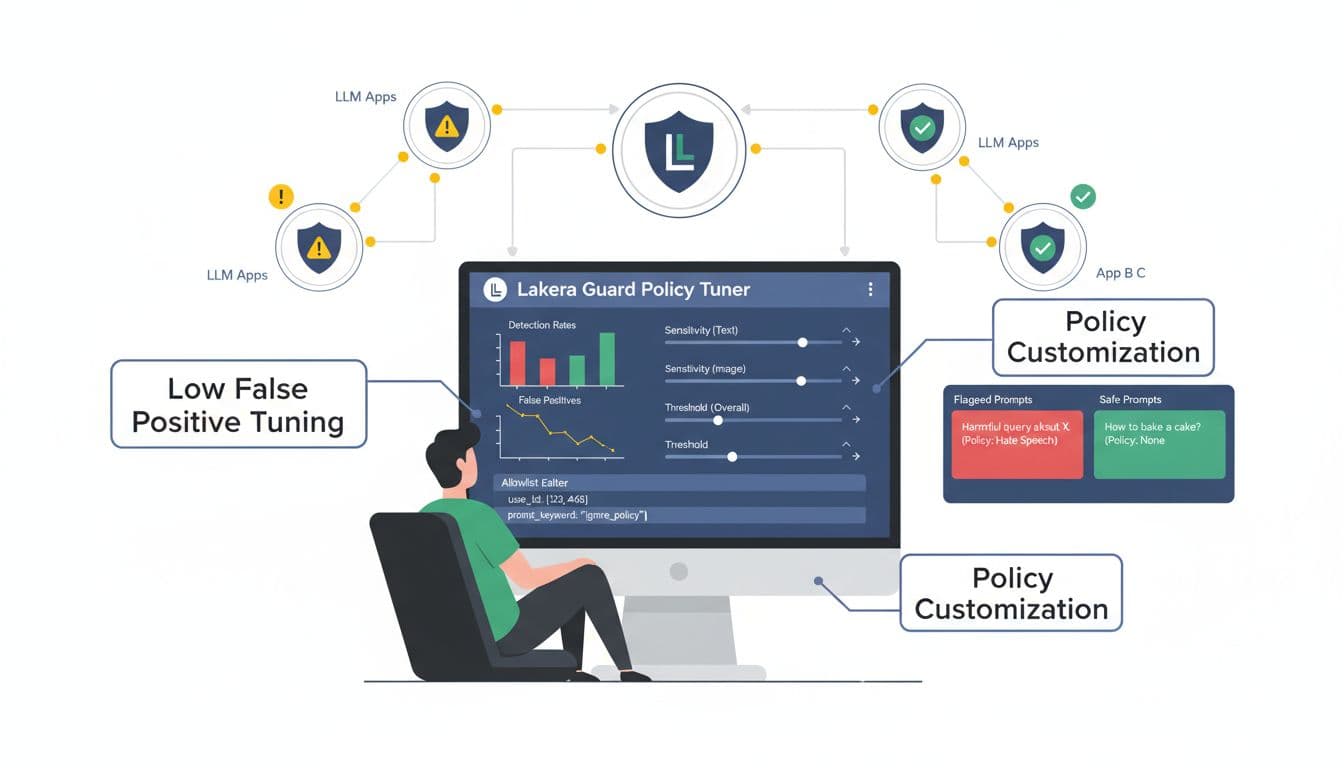
Let’s talk about the part everyone asks me about: false positives.
Public info around early 2026 does not share a universal false-positive rate for Lakera Guard, and that’s not shocking. False positives depend on your app’s domain, your users, and how strict your policies are. A customer support bot, a code assistant, and a red-team training bot will all behave differently.
So I judge this category in a more practical way: how painful are false positives when they happen, and how fast can I tune them down without opening the door to real attacks?
Here’s where false positives tend to show up in real LLM apps:
- Security discussions that quote attack strings (“ignore previous instructions”) as an example
- Developer content that contains payload-like text (API keys formats, shell commands, exploit writeups)
- Policy-heavy apps where users paste internal docs and the guard sees “sensitive-ish” patterns
- Agents with tools where tool output looks instruction-like (a web page that talks in imperative voice)
The good news is that Lakera Guard is described as policy-tunable. In practice, that should mean you can adjust thresholds and add allowlists for known-safe patterns and sources. I also like the idea of a “flag for review” path, instead of hard blocking everything that looks suspicious. For teams with limited time, reducing alert noise matters as much as catching the bad stuff.
This is the same problem I see across security tooling in general: if the signal is good but the noise is high, people mute it. For a wider view on accuracy versus alert fatigue, my notes in this Vectra AI review map pretty well to the LLM guardrails world too.
Setup time and integration: the honest version (including latency)
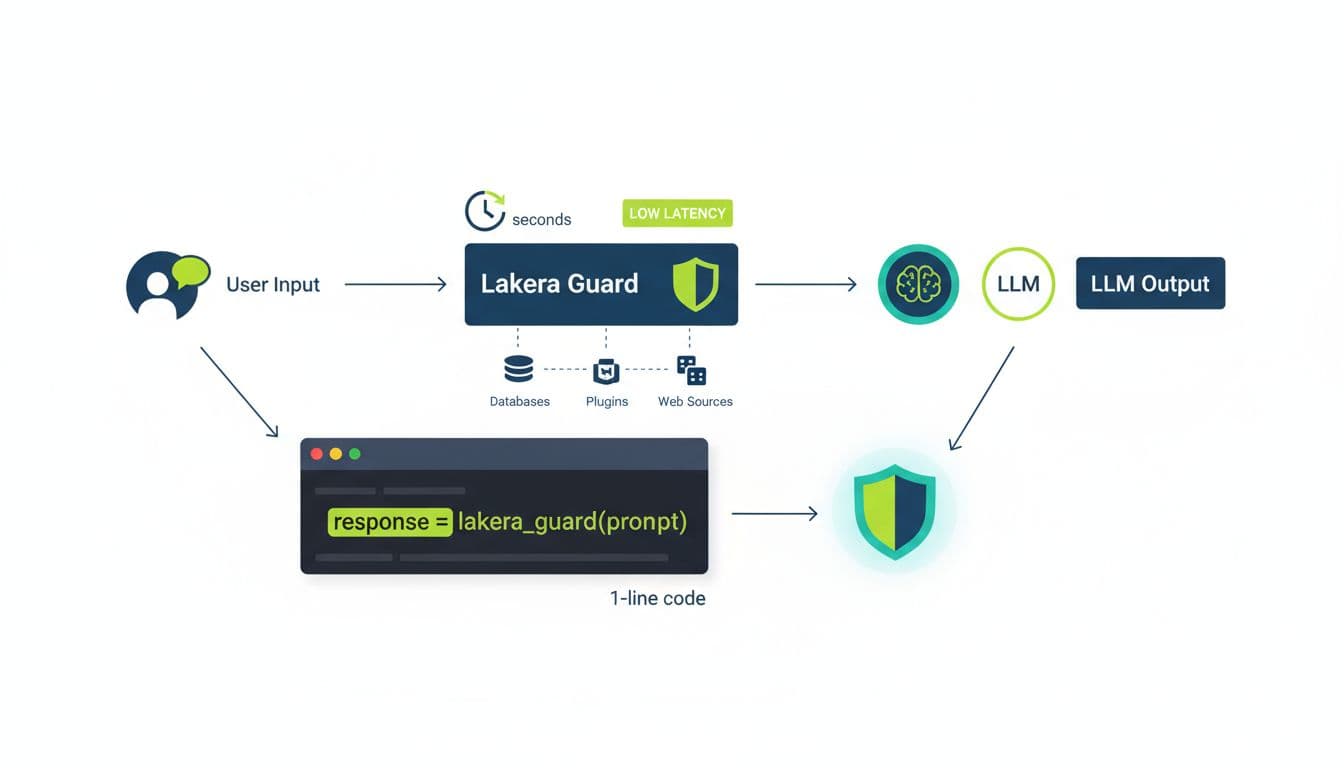
Setup time is where a lot of “security for developers” tools fail. They look great, until you try to wire them into a messy, multi-service app with retries, queues, and several LLM call sites.
Based on current public notes, Lakera Guard is marketed as very fast to integrate (described as a one-line code addition, taking seconds). It’s also positioned as low-latency, reported under 200 ms. That latency number matters because most teams can handle a small per-request cost, but not a sluggish app.
A few integration details stand out in 2026:
1) It’s built for agentic workflows, not only chat.
Tools, browsing, retrieval, and plugins are where indirect injection creeps in.
2) MCP support is a real signal.
Guard is described as securing Model Context Protocol systems by checking inputs and outputs for injection and leakage. If you’re already using MCP servers, that’s a practical fit.
3) It’s not just theory, it’s in real companies.
Dropbox is cited as using it to protect user data in GenAI features. I don’t treat one logo as proof of perfection, but it does suggest it can survive production traffic.
If you’re building chat experiences specifically, it’s worth comparing your threat model against the kinds of bots you deploy. I keep a separate list for that in Best AI chatbots and virtual assistants in 2025, since the risk changes a lot depending on tool access and data access.
Where Lakera Guard fits (and where it doesn’t)
In my Lakera Guard review notes for 2026, I see the best fit as: LLM apps that touch real data and have real actions. If your model can open a ticket, send an email, update a record, or summarize private docs, you want runtime checks.
I also don’t treat Guard as a full security stack. It’s a layer. You still need app security basics, auth, least privilege, logging, and human review paths for risky actions.
A quick way I summarize it:
| Area | What I see in 2026 | What I’d watch |
|---|---|---|
| Setup | Very fast by design | Coverage across all call sites |
| Latency | Reported under 200 ms | Spikes under load, retries |
| Injection defense | Built for direct and indirect attacks | Tool output and RAG sources |
| False positives | No public global rate | Tuning, allowlists, review flow |
For a broader “stack” perspective, I usually compare LLM runtime defense alongside endpoint, identity, and cloud controls. If that’s your angle, my SentinelOne review shows how I think about safety when the whole company is the attack surface, not just the chatbot.
My 2026 take, and what I’d do next
This Lakera Guard review comes down to a simple point: it’s built for the threats LLM apps actually face now, especially indirect prompt injection and agent attacks, and it doesn’t sound painful to deploy. The tradeoff is the usual one, you’ll need policy tuning to keep false positives from annoying users.
If you’re running an app with tools, browsing, or sensitive data, I’d test Lakera Guard on real traffic for a week, then tune policies based on what gets flagged. What would you rather deal with, a few blocked prompts, or one successful injection that turns your agent into a data leak?
















